
En un nuevo artículo de investigación que detalla sus capacidades de entrenamiento de IA para el iPhone y otros productos con funciones de inteligencia artificial anunciados este año, el gigante tecnológico de Cupertino, Apple, al parecer, ha optado por confiar en los chips de Google en lugar de los del líder del mercado NVIDIA. El ascenso de NVIDIA a la cima de la capitalización de mercado La cadena alimentaria de la automatización se basa en la fuerte demanda de sus GPU, que han impulsado los ingresos y las ganancias en porcentajes de tres dígitos.
Sin embargo, en su documento, Apple comparte que su Apple Foundation Model (AFM) de 2.73 mil millones de parámetros se basa en clústeres de nube de unidades de procesamiento tensorial (TPU) v4 y v5p que normalmente proporciona Google de Alphabet Inc.
El enfoque de inteligencia artificial de Apple se basa en el uso de TPU en lugar de GPU, según muestra un documento de investigación
El documento de investigación de Apple, El informe, publicado hoy, cubre su infraestructura de entrenamiento y otros detalles para los modelos de IA que impulsarán las funciones anunciadas en la WWDC a principios de este año. Apple anunció tanto el procesamiento de IA en el dispositivo como el procesamiento en la nube, y en el corazón de estas funciones de IA se encuentra el Modelo de Fundación Apple denominado AFM.
Para AFM en el servidor, o el modelo que impulsará las funciones de IA en la nube llamadas Apple Cloud Compute, Apple compartió que entrena a 6,3 billones de personas Modelo de IA de token «desde cero» en «8192 chips TPUv4». Los chips TPUv4 de Google están disponibles en módulos compuestos de 4096 chips cada uno.
Apple agregó que los modelos AFM (tanto en el dispositivo como en la nube) están entrenados en chips TPUv4 y clústeres de TPU en la nube v5p. v5p es parte de la «hipercomputadora» de IA en la nube de Google y se anunció en diciembre del año pasado.
Cada módulo v5p está compuesto de 8960 chips cada uno y, según Google, ofrece el doble de operaciones de punto flotante por segundo. segundo (FLOPS) y tres veces la memoria sobre TPU v4 para entrenar modelos casi tres veces más rápido.
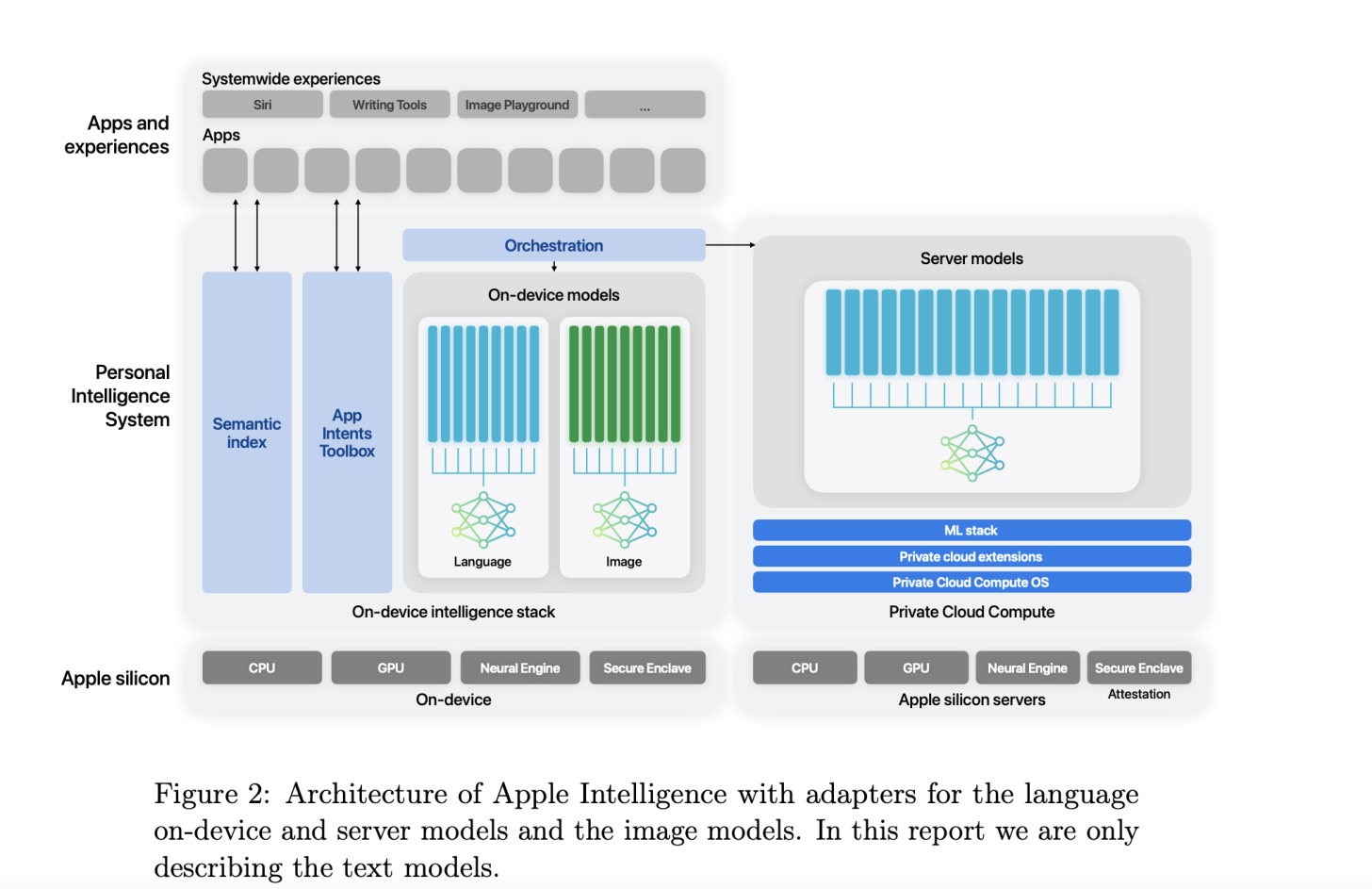
Para el modelo de IA en el dispositivo para funciones como escritura y selección de imágenes, Apple utiliza un modelo de 6.4 mil millones de parámetros que se «entrena desde cero utilizando la misma receta que AF M-server». Apple también optó por confiar en los chips TPU v4 más antiguos para el modelo de servidor AFM. Como se destacó anteriormente, utilizó chips TPU v4 8092, pero para el modelo AFM en el dispositivo, la empresa optó por confiar en los chips más nuevos. Este modelo, según Apple, se entrenó en chips TPU v5p 2048.
Otros detalles compartidos en el documento incluyen la evaluación del modelo para respuestas dañinas, temas sensibles, corrección fáctica, desempeño matemático y satisfacción humana con Resultados del modelo. Según Apple, los modelos de servidor AFM y en el dispositivo están a la cabeza de sus contrapartes de la industria en cuanto a la supresión de resultados dañinos.
Por ejemplo, el servidor AFM, en comparación con GPT-4 de OpenAI, tuvo una tasa de violación de resultados dañinos del 6,3 %, que es significativamente menor que el 28,8 % de GPT-4, según sugieren los datos de Apple. De manera similar, la tasa de violación del 7,5 % de AFM en el dispositivo fue menor que la puntuación del 21,8 % de Llama-3-8B (entrenado por Meta, la matriz de Facebook). En cuanto al resumen de correos electrónicos, mensajes y notificaciones, el AFM en el dispositivo tuvo un porcentaje de satisfacción del 71,3 %, 63 % y 74,9 %, respectivamente. El artículo de investigación indicó que estos resultados superaron a los de los modelos Llama, Gemma y Phi-3.